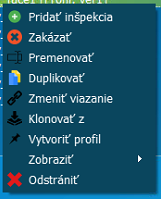
Vytvorenie inšpekcie
Inšpekcie využívajú systém učenia umelej inteligencie pre komplexnú a univerzálnu kontrolu dielcov s potrebou presnosti ako nity, platničky a podobne. Pre jednoduchšie pozície môžeme použiť farebné inšpekcie prítomnosti farby ako napríklad rukoväť prípravkov.
V projektovom strome otvoríme zvolenú inšpekciu

a otvorí sa kamerový obraz a zoznam inšpekcií.
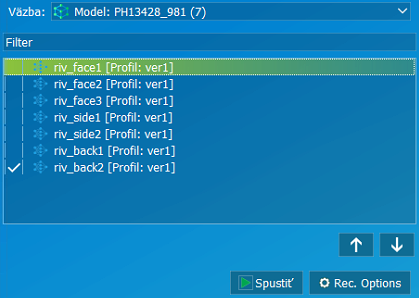
Väzba | Výber skupiny inšpekčných regiónov podľa viazania sa na model, alebo workspace. Pokiaľ je inšpekcia vytvorená priamo v modely tak je viazaná na model a jeho detekciu polohy. Pokiaľ je vytvorená vo workspace, tak je fixne viazaná do pracovného priestoru a nájdeme ju v skupine workspace. |
Spustiť | Spustenie vybraných inšpekcií. |
Rec. Options | Nahrávanie obrázkov datasetu pre učenie umelej inteligencie. |
 | Voľba inšpekcie povoliť / zakázať |
Zakázať / Povoliť | Výber inšpekcie. |
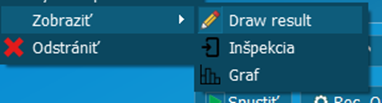
Vlastnosti / Draw result | Vykresliť výsledok inšpekcie do obrazu kamery. |
Vlastnosti / Inšpekcia | Zobraziť inšpekciu v osobitnom okne |
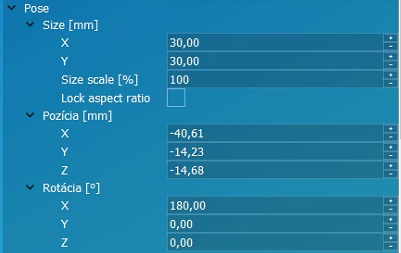
Vlastnosti inšpekcie | |
|---|---|
Pose | Umiestnenie, rotácia a veľkosť inšpekčného regiónu. |
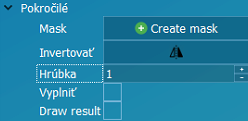
Vlastnosti inšpekcie | |
|---|---|
Pokročilé / Invertovať | Invertovať výsledok inšpekcie. |
Vyplniť | Zaplniť plochu inšpekcie nepriehľadnou farbou výsledku. |
Draw result | Zaplniť plochu inšpekcie priehľadnou farbou výsledku. |
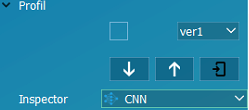
Vlastnosti inšpekcie | ||
|---|---|---|
Profil / ver1 | Selekcia a voľba spoločného profilu inšpekcií. | |
Inspector | Typ inšpekcie: | |
CNN | umelá inteligencia | |
Farba | farebná inšpekcia | |
Vytvorenie farebnej inšpekcie
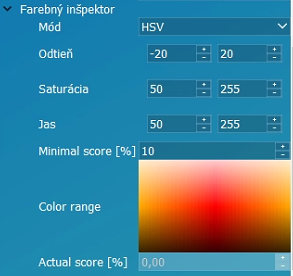
Mód | Farebný formát odporúčaný HSV. |
Odtieň, Saturácia, Jas | Ohraničenie nameraných hodnôt z obrazu. |
Min. score | Minimálne výsledné skóre potrebné na potvrdenie inšpekcie. |
Color range | Zobrazenie farebného ohraničenia. |
Actual score | Aktuálne namerané skóre. |
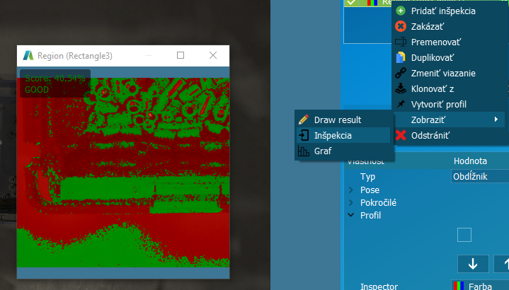
Zobrazením inšpekčného okna vieme dynamicky zvoliť rozsah požadovanej farby. Stlačením tlačidla Ctrl + kliknutie na požadovanú farbu rozširujeme rozsah farebného ohraničenia.
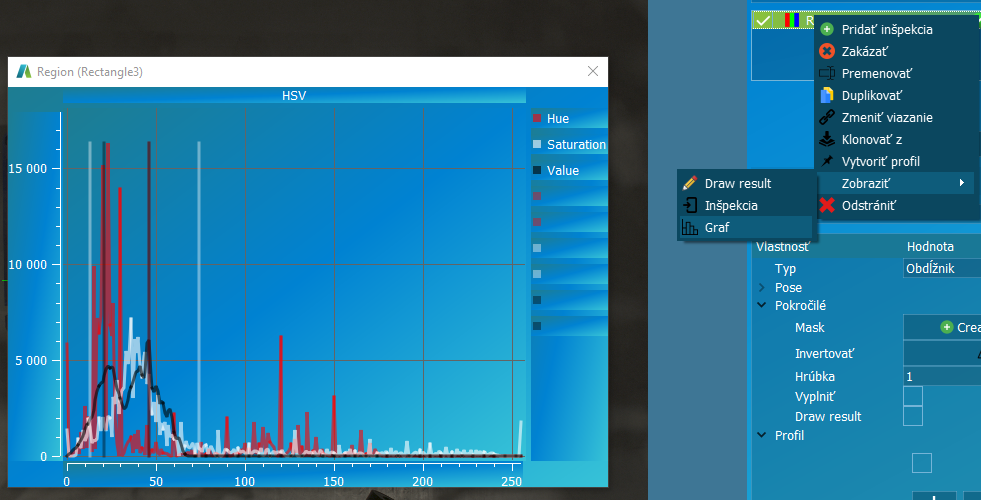
Zobrazenie grafu umožňuje vizualizovať rozsah ohraničenia a aktuálnu farebnú konfiguráciu.
Vytvorenie CNN inšpekcie
Inspector | CNN typ umelá inteligencia | |
CNN Inšpektor | Trénovať | Otvoriť trénovacie okno. |
Export | Exportovať model CNN. | |
Vymazať | Vymazať model CNN | |
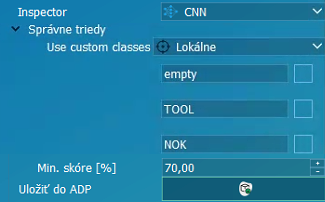
Správne triedy / Use custom classes / | |
|---|---|
Lokálne | Nastavenie trénovanej správnej tiredy modelu CNN. |
Globálne | Použiť správnu triedu nastavenú v profile. |
TOOL | Selekcia správnej triedy. |
Min. score | Minimálne výsledné skóre potrebné na potvrdenie inšpekcie. |
Použitie profilu
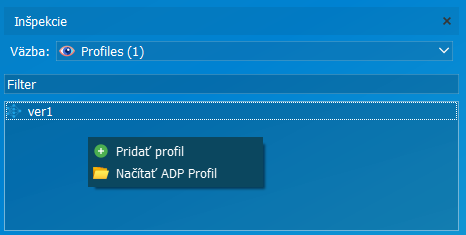
Použitím profilu umožníme zdieľať rovnaké inšpekčné nastavenia viacerým inšpekčným regiónom. Profily sú uložené v rámci projektu a každý projekt má vlastné.
Architektúra CNN inšpekcií pre aplikáciu nitovanie
Každá CNN inšpekcia potrebuje natrénovaný model, ktorý obsahuje triedy, ktoré predstavujú výsledok rozpoznania obrazu (auto, lietadlo, atď…). Takéto triedy musíme vytvoriť trénovaním pomocou vytvorených fotiek, ktoré predstavujú objekt danej triedy. Súbor takýchto fotiek sa volá Dataset.
Dataset môže byť spoločný pre rôzne CNN modely, alebo unikátny. Je to priečinok na disku, ktorý obsahuje kategorizovane zoradené fotky tried v priečinkoch podľa ktorého sa trénujú CNN modely.
V rámci projektu nitovania používame jeden dataset „rivet“, ktorý obsahuje všetky spojovacie prvky ako nity, skrutky, etc.... Tento dataset je spoločný pre všetky CNN modely projektov a je potrebné ho udržovať nemenný, len pridávať triedy, ale pôvodné nemeniť. Každé trénovanie projektov používa tento spoločný dataset a preto zmena projektu X bude vplývať na projekt Y.
Všetky ostatné komponenty ako konzoly, prípravky atď. sú držané v lokálnom CNN modely a datasete v priečinku určenom len pre daný projekt.
Vytváranie Datasetu
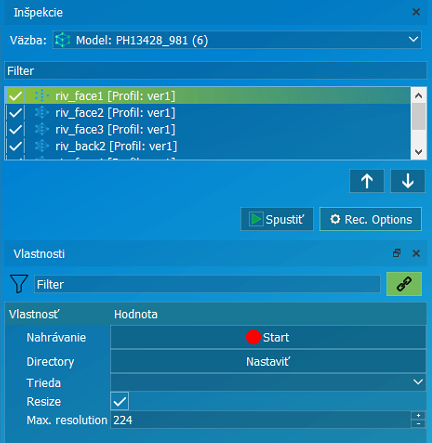
Rec. Options | Tlačidlo pre otvorenie možností nahrávania. |
Nahrávanie | Spustenie nahrávania obrázkov z vybraných inšpekčných regiónov. |
Directory | Voľba priečinku datasetu. |
Trieda | Zvoliť si preddefinovanú triedu, Good/Bad/Empty, alebo si vytvoriť vlastnú. |
Resize a Max. Resolution | Nemeniť. |
Príprava trénovania CNN modelu
Okno trénovania CNN modelu pozostáva z časti zobrazenia datasetu a konfigurácie trénovania.
Dataset pozostáva z trénovacej časti a validačnej. Trénovací dataset slúži pre učenie a validačný pre kontrolu učenia. Každá fotka z trénovacieho datasetu je upravená podľa parametrov tak, aby simulovala možné obmeny v rámci živého obrazu.
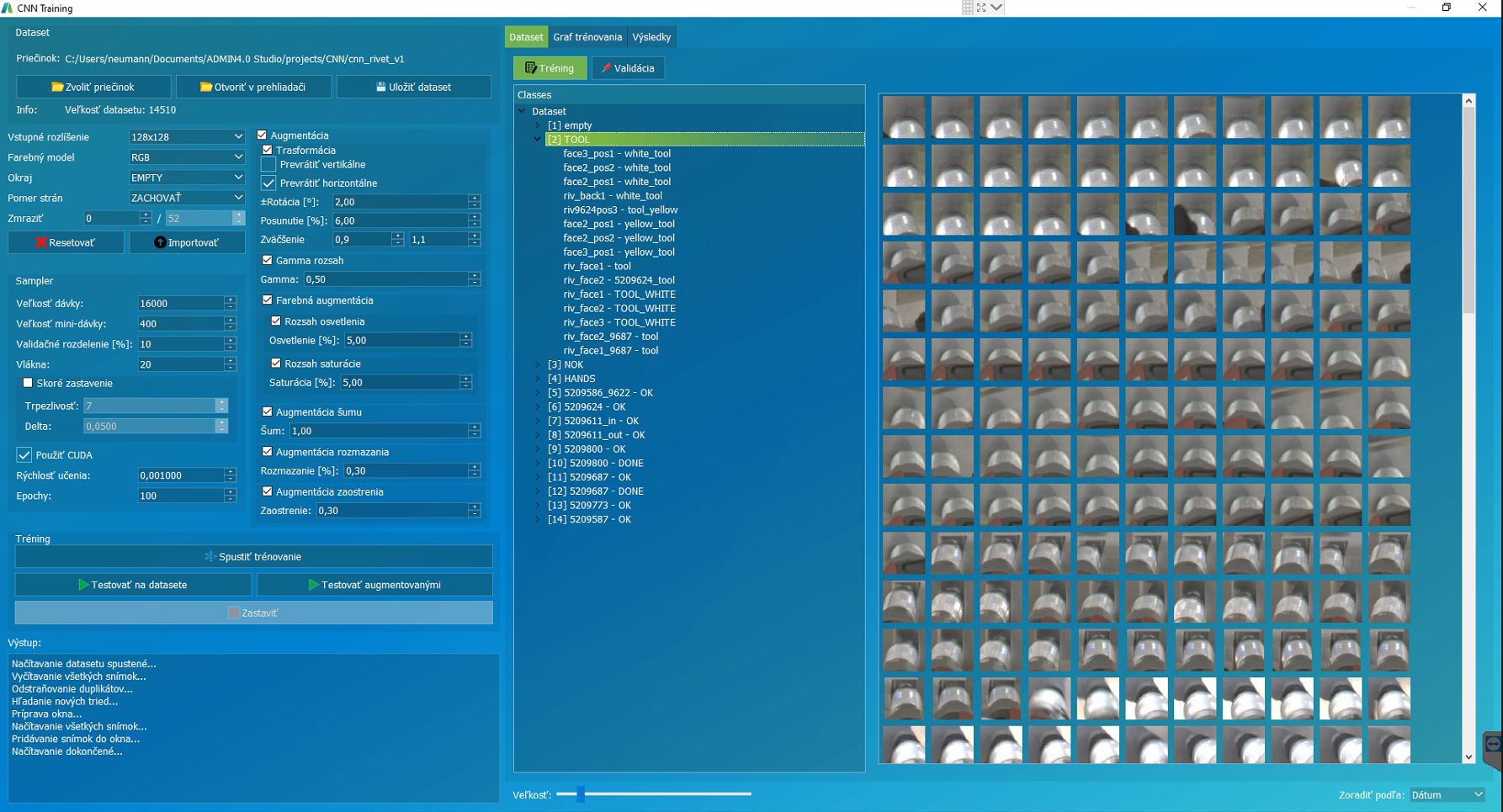
Dataset – výber zdrojového adresára
V tejto časti vyberáme dataset, podľa ktorého budeme trénovať CNN model.

Prepínanie medzi tréningovým a validačným datasetom.
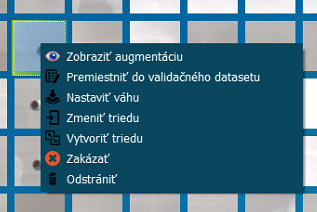
Vlastnosti zobrazovaných obrázkov datasetu
Premiestniť do val. datasetu | Funkcia premiestni vybranú fotku/fotky do validačného datasetu. |
Nastaviť váhu | Zvýši mieru učenia na vybranú fotku, používa sa v prípade nových fotiek na ktoré chceme doúčať CNN model. Nové fotky v datasete sú vždy vyznačené zelenou farbou a pokiaľ chceme urýchliť trénovanie im môžeme dať váhu 10. Nezabudnúť váhu po trénovaní nastaviť na nulu prípadne nižšie číslo. |
Zakázať | Fotka ostane zašednutá a nebude sa používať na trénovanie. |
Funkcie triedy | V vytváranie tried učenia. |
Odstrániť | Vymazať. |
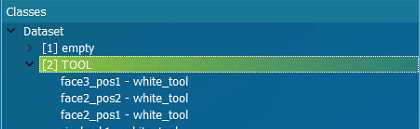
Zobrazenie tried v strome datasetu. Všetky fotky zobrazíme kliknutím na položku Dataset.
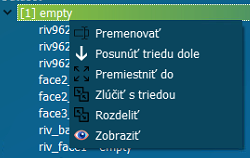
Práca s jednotlivými triedami v strome
datasetu
Posunúť triedu dole / hore | Táto funkcia priamo zasahuje to indexácie tried a teda do projektov. Ak zmeníme poradie tried tak sa stratí väzba s projektom. |
Premiestniť do | Triedu môžeme premiestniť do inej triedy. |
Zlúčiť | Dve triedy vieme zlúčiť do jednej skupinovej triedy. |
Rozdeliť | Naopak vieme rozdeliť skupinu na dve osobitné triedy tak ako pred zlúčením. |
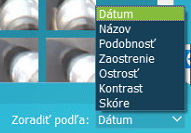

Práca s fotkami a zmena ich veľkosti ikony a ich zoradenie v zobrazení podľa:
Dátum, Názov
Podobnosť – Fotky s predpokladom najväčšej podobnosti teda najmenších známok rozdielov sú zobrazené ako prvé.
Zaostrenie – Najrozmazanejšie fotky sú zobrazené ako prvé.
Ostrosť / Kontrast – Triedenie podľa kvality fotky.
Skóre – Po spustení:

dostane každá fotka v datasete pridelené číslo úspešnosti (skóre) podľa ktorého si vieme zoradiť fotky a určiť tak fotky s najnižším skóre a rozhodnúť sa či majú dôležitosť pre učenie, alebo sú zlé.
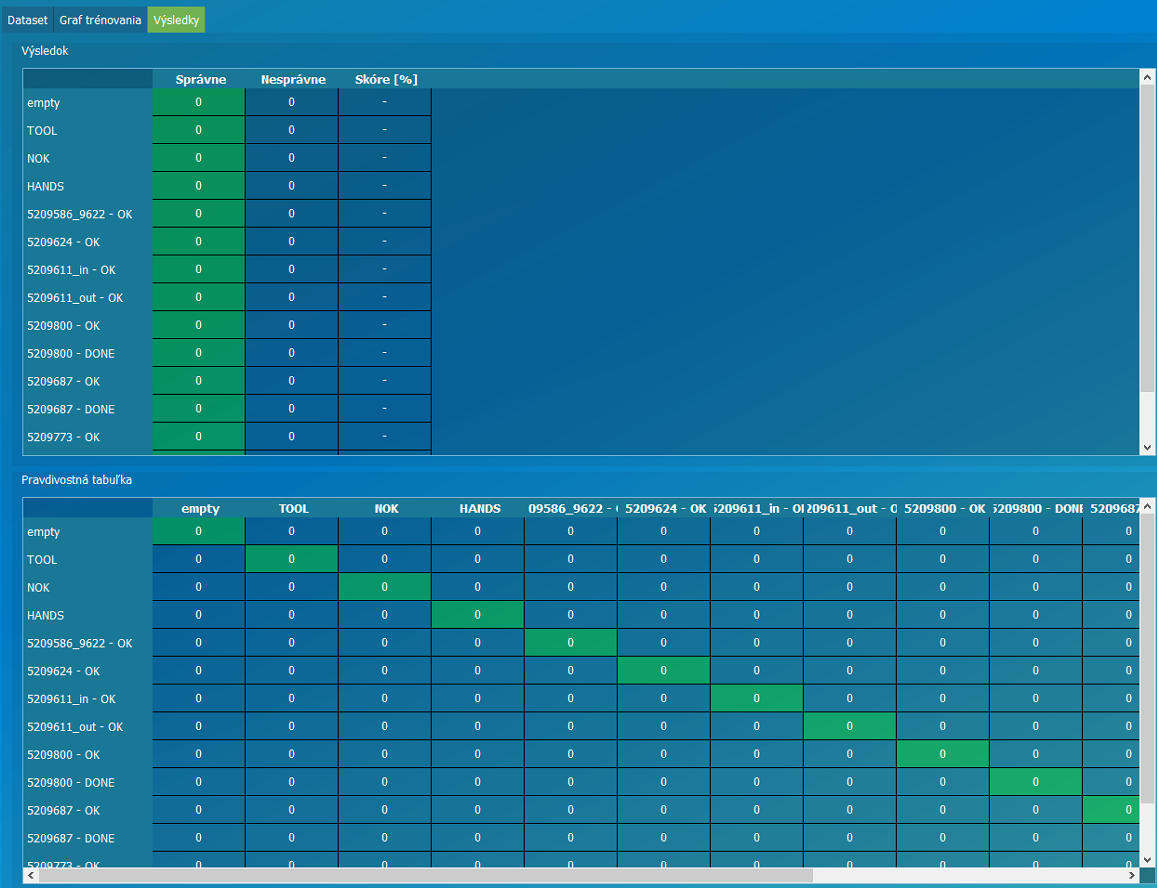
Záložka výsledky trénovania – Po spustení testovania na datasete je skóre každej fotky štatisticky zobrazené v tabuľke výsledkov.
Spustenie trénovania CNN modelu
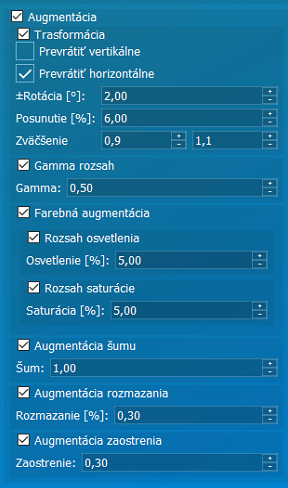
Augmentácia | Rozširovanie učenia na základe poznaných fotiek je dôležitá funkcia, kde pomocou určených parametrov upravujeme fotky tak aby simulovali zmenu prostredia: |
Transformácia | Objekt je potrebné zobraziť pri učení aj v iných pozíciách ako len tej, ktorú poznáme. |
Prevrátiť vertikálne / horizontálne | Preklopenie fotky cez V/H os. |
Rotácia / Posunutie / Zväčšenie | Rozmerová a pozičná úprava fotky. |
Gamma rozsah | Úprava farebnej kvality fotiek. |
Rozsah osvetlenia | Simulácia zmeny jasových podmienok pracovného prostredia. |
Saturácia | Úprava kvality farieb fotky. |
Šum / Rozmazanie / Zaostrenie | Simulácia zhoršených podmienok pracoviska. |
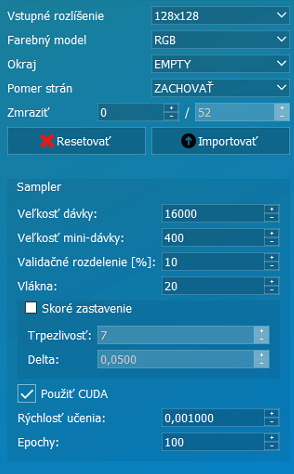
Parametre učenia | |
|---|---|
Resetovať | Resetovať model CNN. |
Importovať | Importovať model CNN. |
Veľkosť dávky | Veľkosť dávky musí obsiahnuť počet fotiek v datasete teda ak máme 13954 fotiek v datasete tak nastavíme hodnotu 14000. |
Mini-dávka | Je objem fotiek použitých na jedno trénovanie, teda celková veľkosť dávky je rozdelená na mini-dávky o veľkosti závislej na použitej grafickej karte a jej pamäti. |
Validačné rozdelenie | V prípade, že máme prázdnu validačnú triedu, systém automaticky určí percentuálny počet fotiek, ktorý premení na validačné. |
Použiť CUDA | Áno. Trénovanie na GPU. |
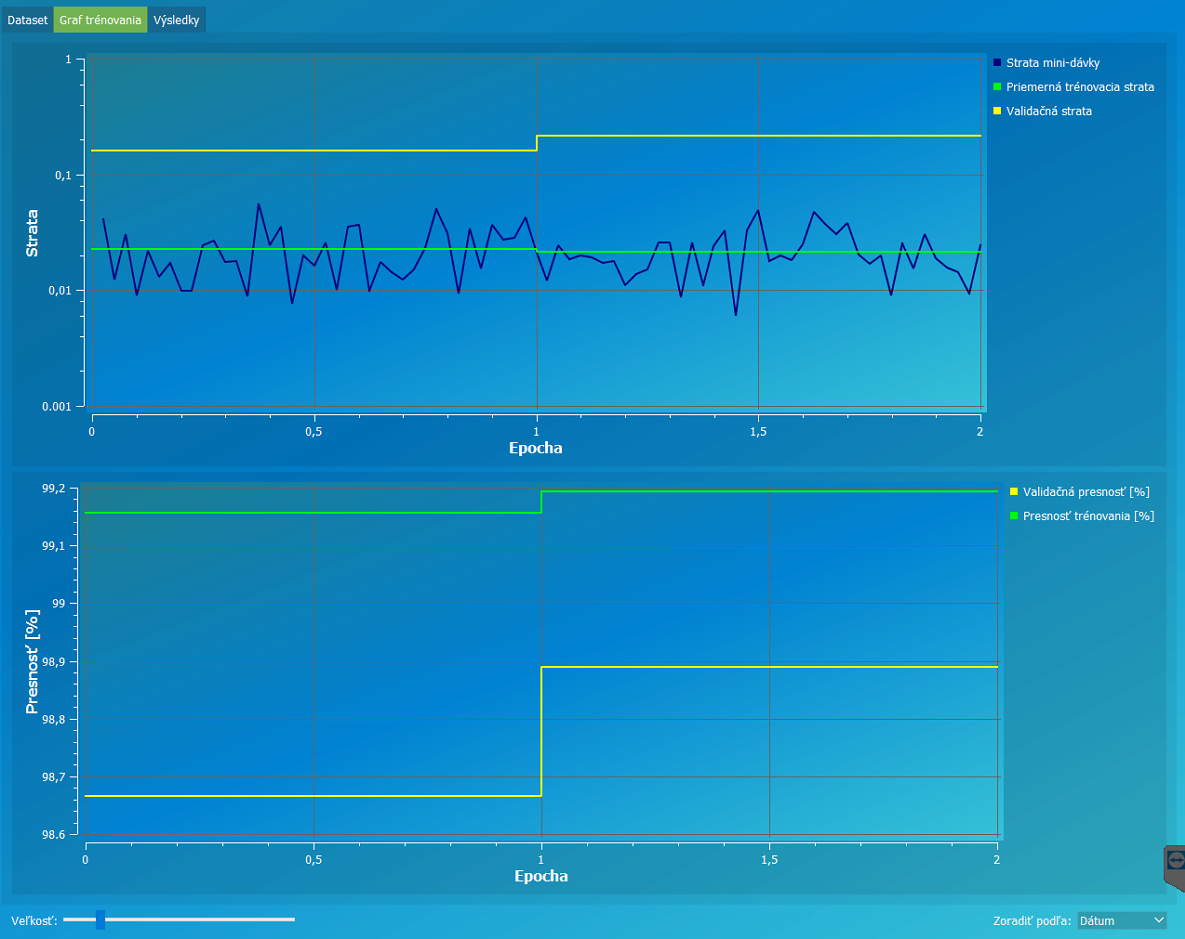
Priebeh trénovania. Strata predstavuje stratu pre jednotlivú mini-dávku trénovania na trénovacích a validačných dátach. Táto strata musí klesať pokiaľ učenie prebieha dobre.
Presnosť trénovania naopak stúpa s počtom trénovaní a očakávaná úroveň je cez 99% avšak je závislá na kvalite datasetu.